commit: 34deef3fbc3f999f804e1e14644632602371e995
parent 485102ba6163e4e0d9d73bda5a697e637b4fafb0
Author: Drew DeVault <sir@cmpwn.com>
Date: Tue, 15 Mar 2022 11:48:53 +0100
Status update: March 2022
Diffstat:
1 file changed, 158 insertions(+), 0 deletions(-)
diff --git a/content/blog/Status-update-March-2022.md b/content/blog/Status-update-March-2022.md
@@ -0,0 +1,158 @@
+---
+title: Status update, March 2022
+date: 2022-03-15
+---
+
+Greetings! The weather is starting to warm up again, eh? I'm a bit disappointed
+that we didn't get any snow this winter. Yadda yadda insert intro text here.
+Let's get down to brass tacks. What's new this month?
+
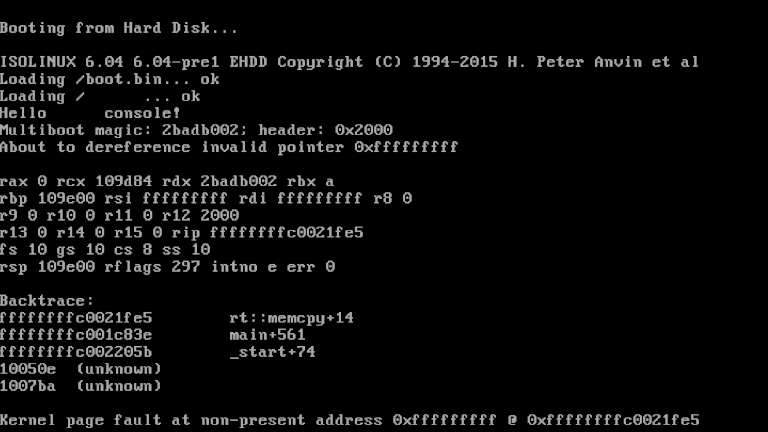
+I mainly focused on the programming language this month. I started writing a
+kernel, which you can see a screenshot of below. This screenshot shows a
+simulated page fault, demonstrating that we have a working interrupt handler,
+and also shows something mildly interesting: backtraces. I need to incorporate
+this approach into the standard library as well, so that we can dump useful
+stack traces on assertion failures and such. I understand that someone is
+working on DWARF support as well, so perhaps we'll soon be able to translate
+function name + offset into a file name and line number.
+
+
+
+I also started working on a PNG decoder this weekend, which at the time of
+writing can successfully decode 77 of the 161 PNG test vectors. I am quite
+pleased with how the code turned out here: this library is a good demonstration
+of the strengths of the language. It has simple code which presents a
+comprehensive interface for the file format, has a strong user-directed memory
+management model, takes good advantage of features like slices, and makes good
+use of standard library features like compress::zlib and the I/O abstraction. I
+will supplement this later with a higher level image API which handles things
+like pixel format conversions and abstracting away format-specific details.
+
+<details>
+ <summary>Expand for a sample from image::png</summary>
+
+```hare
+use bufio;
+use bytes;
+use compress::zlib;
+use errors;
+use io;
+
+export type idat_reader = struct {
+ st: io::stream,
+ src: *chunk_reader,
+ inflate: zlib::reader,
+ decoder: *decoder,
+};
+
+// Returns a new IDAT reader for a [[chunk_reader]], from which raw pixel data
+// may be read via [[io::read]]. The user must prepare a [[decoder]] object
+// along with a working buffer to store the decoder state. For information about
+// preparing a suitable decoder, see [[newdecoder]].
+export fn new_idat_reader(
+ cr: *chunk_reader,
+ decoder: *decoder,
+) (idat_reader | io::error) = {
+ assert(cr.ctype == IDAT, "Attempted to create IDAT reader for non-IDAT chunk");
+ return idat_reader {
+ st = io::stream {
+ reader = &idat_read,
+ ...
+ },
+ src = cr,
+ inflate = zlib::decompress(cr)?,
+ decoder = decoder,
+ };
+};
+
+fn idat_read(
+ st: *io::stream,
+ buf: []u8,
+) (size | io::EOF | io::error) = {
+ let ir = st: *idat_reader;
+ assert(ir.st.reader == &idat_read);
+ let dec = ir.decoder;
+ if (dec.buffered != 0) {
+ return decoder_copy(dec, buf);
+ };
+
+ if (dec.filter is void) {
+ const ft = match (bufio::scanbyte(&ir.inflate)) {
+ case io::EOF =>
+ return idat_finish(ir);
+ case let b: u8 =>
+ yield b: filter;
+ };
+ if (ft > filter::PAETH) {
+ return errors::invalid;
+ };
+ dec.filter = ft;
+ };
+
+ // Read one scanline
+ for (dec.read < len(dec.cr)) {
+ match (io::read(&ir.inflate, dec.cr[dec.read..])?) {
+ case io::EOF =>
+ // TODO: The rest of the scanline could be in the next
+ // IDAT chunk. However, if there is a partially read
+ // scanline in the decoder and no IDAT chunk in the
+ // remainder of the file, we should probably raise an
+ // error.
+ return idat_finish(ir);
+ case let n: size =>
+ dec.read += n;
+ };
+ };
+
+ applyfilter(dec);
+ dec.read = 0;
+ dec.buffered = len(dec.cr);
+ return decoder_copy(dec, buf);
+};
+
+fn idat_finish(ir: *idat_reader) (io::EOF | io::error) = {
+ // Verify checksum
+ if (io::copy(io::empty, ir.src)? != 0) {
+ // Extra data following zlib stream
+ return errors::invalid;
+ };
+ return io::EOF;
+};
+
+@test fn idat_reader() void = {
+ const src = bufio::fixed(no_filtering, io::mode::READ);
+ const read = newreader(&src) as reader;
+ let chunk = nextchunk(&read) as chunk_reader;
+ const ihdr = new_ihdr_reader(&chunk);
+ const ihdr = ihdr_read(&ihdr)!;
+
+ let pixbuf: []u8 = alloc([0...], decoder_bufsiz(&ihdr));
+ defer free(pixbuf);
+ let decoder = newdecoder(&ihdr, pixbuf);
+
+ for (true) {
+ chunk = nextchunk(&read) as chunk_reader;
+ if (chunk_reader_type(&chunk) == IDAT) {
+ break;
+ };
+ io::copy(io::empty, &chunk)!;
+ };
+
+ const idat = new_idat_reader(&chunk, &decoder)!;
+ const pixels = io::drain(&idat)!;
+ defer free(pixels);
+ assert(bytes::equal(pixels, no_filtering_data));
+};
+```
+
+</details>
+
+In SourceHut news, I completed our migration to Alpine 3.15 this month after a
+brief outage, including an upgrade to our database server, which is upgraded on
+a less frequent cadance than the others. Thanks to Adnan's work, we've also
+landed many GraphQL improvements, mainly refactorings and other like
+improvements, setting the stage for the next series of roll-outs. I plan on
+transitioning back from focusing on the language to focusing on SourceHut for
+the coming month, and I expect to see some good progress here.
+
+That's all I have to share for today. Until next time!